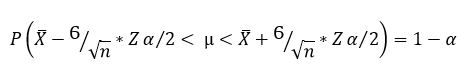¿Qué es?
Una prueba de hipótesis es
una regla que especifica si se puede aceptar o rechazar una afirmación acerca
de una población dependiendo de la evidencia proporcionada por una muestra de
datos.
Una prueba de hipótesis
examina dos hipótesis opuestas sobre una población: la hipótesis nula y la
hipótesis alternativa. La hipótesis nula es el enunciado que se probará. Por lo
general, la hipótesis nula es un enunciado de que "no hay efecto" o
"no hay diferencia". La hipótesis alternativa es el enunciado que se
desea poder concluir que es verdadero de acuerdo con la evidencia proporcionada
por los datos de la muestra.
Con base en los datos de
muestra, la prueba determina si se puede rechazar la hipótesis nula. Usted
utiliza el valor p para tomar esa decisión. Si el valor p es menor
que el nivel de significancia (denotado como α o alfa), entonces puede rechazar
la hipótesis nula.
Un error común de
percepción es que las pruebas estadísticas de hipótesis están diseñadas para
seleccionar la más probable de dos hipótesis. Sin embargo, al diseñar una
prueba de hipótesis, establecemos la hipótesis nula como lo que queremos
desaprobar. Puesto que establecemos el nivel de significancia para que sea
pequeño antes del análisis (por lo general, un valor de 0.05 funciona
adecuadamente), cuando rechazamos la hipótesis nula, tenemos prueba estadística
de que la alternativa es verdadera. En cambio, si no podemos rechazar la
hipótesis nula, no tenemos prueba estadística de que la hipótesis nula sea
verdadera. Esto se debe a que no establecimos la probabilidad de aceptar
equivocadamente la hipótesis nula para que fuera pequeña.
Una prueba de hipótesis
comprende cuatro componentes principales:
-Hipótesis Nula
-Hipótesis Alternativa
-Estadística de Prueba
-Región de Rechazo

La
Hipótesis Nula
Denotada como H0 siempre especifica un solo valor
del parámetro de la población si la hipótesis es simple o un conjunto de
valores si es compuesta.
H0
:µ = µ0 H0 :µ ≤ µ0 H0
:µ ≥ µ0
La
Hipótesis Alternativa
Denotada como H1 es la que responde nuestra
pregunta, la que se establece en base a la evidencia que tenemos. Puede tener
cuatro formas:
H1:
µ= µ1 H1: µ< µ0 H1: µ> µ0 H1: µ≠ µ0
La Estadística de Prueba
Es una estadística que se deriva del estimador puntual del parámetro que estemos probando y en ella basamos nuestra decisión acerca de si rechazar o no rechazar la Hipótesis Nula.
La Región de Rechazo
Es una estadística que se deriva del estimador puntual del parámetro que estemos probando y en ella basamos nuestra decisión acerca de si rechazar o no rechazar la Hipótesis Nula.
La Región de Rechazo
Es el conjunto de valores tales que si la prueba estadística
cae dentro de este rango, decidimos rechazar la Hipótesis Nula Su localización
depende de la forma de la Hipótesis Alternativa: Si H1: µ> µ0
entonces la región se encuentra en la cola derecha de la distribución de la
estadística de prueba.

Hipótesis Estadísticas Derivadas
Se les
denomina así a los supuestos (hipótesis) realizados con respecto a un parámetro
o estadístico (media, proporción, entre otros).
En este paso
se definen dos tipos de hipótesis:
·
Ho: Hipótesis nula
·
H1: Hipótesis alterna (de la cual
se sospecha pudiera ser cierta, es planteada por el investigador)
Nivel de Significancia (α)
Se le conoce
así al error máximo adoptado al momento de rechazar la hipótesis nula (Ho)
cuando es verdadera.
Dependiendo
del tipo de significación que se da al estudio, hay tres grados:
·
α = 0.01 → Demasiado significativo
·
α = 0.05 → Significativo
·
α = 0.10 → Poco significativo

Valor de la
distribución Z o t
En este paso
se procede a ubicar el intervalo de confianza para su próxima colocación en el
gráfico de "aceptación y rechazo".
Hay dos
formas de encontrar dicho valor: mediante la tabla "Z" o
la tabla "t".
Para definir
cuál es la tabla en la que se buscará la información, se debe de considerar el
número de datos con los que se cuenta.
·
Si la cantidad de datos sobrepasa o es igual a 30, se
usará la tabla "Z"
·
Si la cantidad de datos son menores a 30, se usará la
tabla "t".
Determinar el intervalo de confianza
El intervalo de
confianza es el punto que separa a la Región de Aceptación y Rechazo.
·
Para una variable:
Tabla Z
Para hallar el
intervalo en esta tabla se sigue la siguiente fórmula:
Z= α
Donde:
α = Nivel de significancia
Tabla t
Para hallar el
intervalo en la tabla t-student se sigue la siguiente fórmula:
Para cuando H1 es " < " o
" > "
|
Para cuando H1 es " ≠ "
|
t= (n-1),(1 -α/1)
|
t= (n-1),(1 -α/2)
|
Donde:
α = Nivel de significancia
n = Cantidad de datos |
Donde:
α = Nivel de significancia
n = Cantidad de datos |
·
Para dos variables:
Tabla Z
Para hallar el
intervalo en esta tabla se sigue la siguiente fórmula:
Para usar esta
fórmula, tanto n1 y n2 tienen que tener un
valor mayor o igual a 30 n1 ≥
30
n2 ≥ 30
n2 ≥ 30
Z= α
|
Donde:
α = Nivel de significancia
|
Tabla t
Para hallar el intervalo en la tabla t-student se sigue
la siguiente fórmula:
Para usar esta fórmula, por lo menos n1 o n2 tiene
que tener un valor inferior a 30
n1 <30
n2 <30
n2 <30
t= (n1+n2-2),(1
-α/1)
|
t= (n1+n2-2),(1
-α/2)
|
Donde:
α = Nivel de significancia
n = Cantidad de datos |
Donde:
α = Nivel de significancia
n = Cantidad de datos |
Estadística
de prueba “Z” o “t”
·
Una media o promedio
Para muestras mayores o igual a 30

Donde:
𝜒= Promedio parcial (de la muestra)
𝜎= Desviación poblacional total
µ= Valor de la hipótesis
n = Número de datos
Para muestras menores a 30

Donde:
𝜒= Promedio parcial (de la muestra)
S = Desviación de la muestra
µ= Valor de la hipótesis
n= Número de datos
S = Desviación de la muestra
µ= Valor de la hipótesis
n= Número de datos
·
Una proporción o porcentaje
Para muestras mayores o igual a 30

Donde:

Si el problema no lo da, se puede
conseguir de la siguiente forma:

𝜒= Valor numérico de la muestra
P0 = Proporción poblacional (total)
n= Número de datos
P0 = Proporción poblacional (total)
n= Número de datos
Para muestras menores a 30

Donde:

Si el problema no lo da, se puede
conseguir de la siguiente forma:

𝜒= Valor numérico de la muestra
P0 = Proporción poblacional (total)
n= Número de datos
P0 = Proporción poblacional (total)
n= Número de datos
·
Diferencia de dos
medias o promedios

Donde:
𝜒1= Promedio de la primera variable
𝜒2 = Promedio de la segunda variable
𝑼1 = Porcentaje de la primera variable (si no se especifica es 100 (%))
𝜒2 = Promedio de la segunda variable
𝑼1 = Porcentaje de la primera variable (si no se especifica es 100 (%))
𝑼2= Porcentaje de la segunda
variable (si no se especifica es 100 (%))
𝜎1 = Desviación de la primera variable
𝜎2 = Desviación de la segunda variable
n1 = Número de datos de la primera variable (total)
n2 = Número de datos de la segunda variable (total)
𝜎1 = Desviación de la primera variable
𝜎2 = Desviación de la segunda variable
n1 = Número de datos de la primera variable (total)
n2 = Número de datos de la segunda variable (total)
·
Diferencia de
proporciones o porcentajes



Se puede conseguir de la siguiente forma, si es
un porcentaje:

𝜒1= Promedio de la primera variable en porcentaje
𝜒2= Promedio de la segunda variable en porcentaje
𝜒2= Promedio de la segunda variable en porcentaje
𝑼1= Porcentaje de la primera variable
(si no se especifica es 100 (%))
𝑼2= Porcentaje de la segunda variable (si no se especifica es 100 (%))
n1= Número de datos de la primera variable (total)
n2= Número de datos de la segunda variable (total)
𝑼2= Porcentaje de la segunda variable (si no se especifica es 100 (%))
n1= Número de datos de la primera variable (total)
n2= Número de datos de la segunda variable (total)
Importancia
El tipo exacto de la prueba estadística utilizada
depende de muchos factores, incluyendo el campo, el tipo de datos y el tamaño de la muestra, entre otros.
La gran mayoría de la investigación
científica es finalmente probada por
métodos estadísticos y todos brindan un grado de confianza en los resultados.
En la mayoría de las disciplinas, el investigador
busca un nivel de significación de 0,05, lo que significa que sólo hay una
probabilidad del 5% de que los resultados y las tendencias observadas se
produjeran de casualidad.
En el caso de algunas disciplinas
científicas, el nivel requerido es de 0,01, apenas un 1% de probabilidad de que
los patrones observados ocurrieran debido a la casualidad o a un error. El
nivel de significación, cualquiera sea, determina si la nula o la alternativa es
rechazada, una parte crucial de la prueba de la hipótesis.